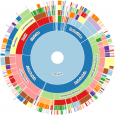
A collection of open-access, curated databases that integrate population sequence data with provenance and phenotype information for over 140 different microbial species and genera.
44,202,858
1,895,034
1,398,137